


FHIR-Based Data Platform for Roche: Standardizing Patient Data Across 650+ Facilities
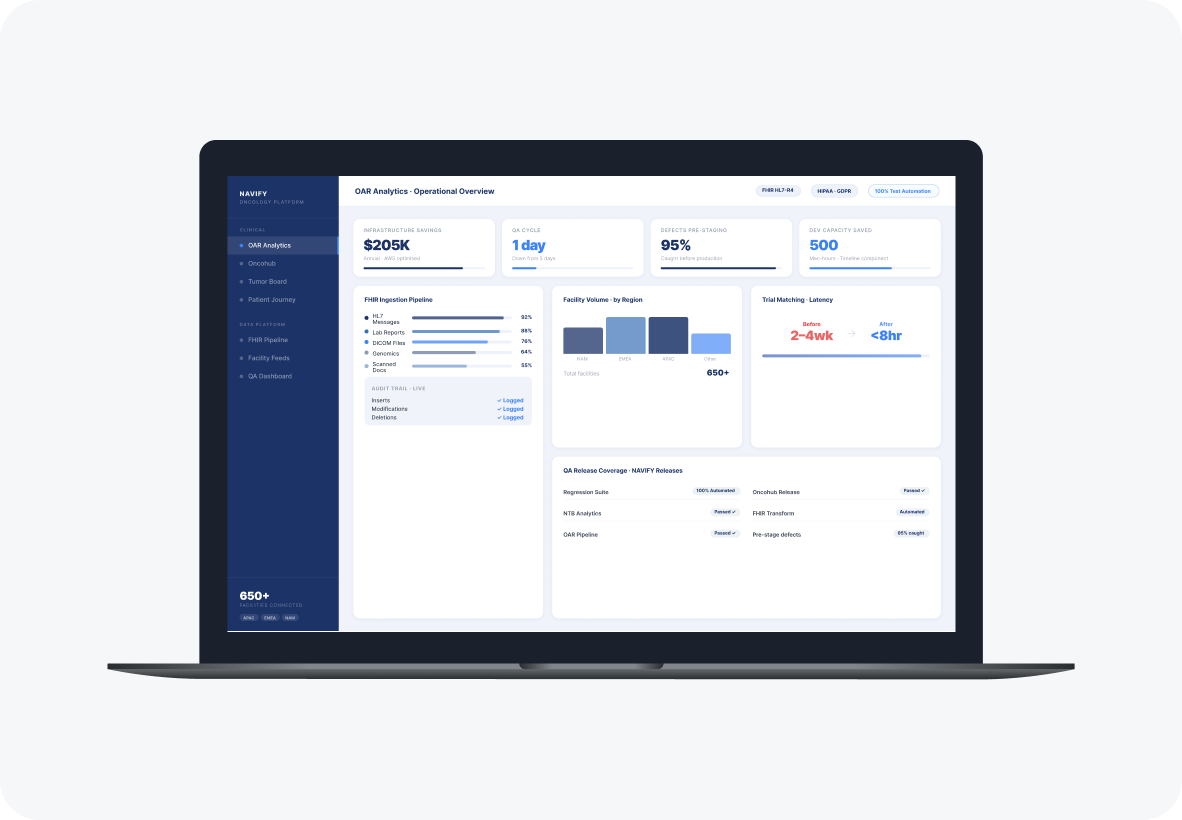
Roche's NAVIFY products ingested patient data from hundreds of hospitals in incompatible formats and had no unified patient record. Ideas2IT built the standardization, enrichment, and analytics platform that resolved it, cut infrastructure costs by $205K per year, and compressed QA cycles from 5 days to 1.

Client
Roche (NAVIFY)

Industry
Healthcare

Service
Data Engineering

Team
64 engineers · 3 squads

Engagement
Active · Ongoing
01 Challenge
Roche's clinical teams had no unified view across EMRs, genomic labs, hospital chains, and insurance systems. Trial matching took 2 to 4 weeks, tumor board decisions were inconsistent, and every layer had to meet HIPAA, GDPR, and 21 CFR Part 11 inside an organization where the bar for enterprise software is high.
02 Solution
Ideas2IT built the platform in layers, each unlocking the next. A HIPAA and GDPR-compliant AWS data lake converted patient records from across Roche's ecosystem into FHIR HL7-R4 format. An AI matching engine, NLP query interface, oncology guidelines layer, and longitudinal patient journey platform built on top, bringing clinical intelligence to the point of care.
03 Outcome
Patient-to-trial matching dropped from 2 to 4 weeks to under 8 hours. Protocol search time fell 60% and decision-making speed increased 2.5x across Roche's clinical and business teams.
Phase 01
Building a compliant, unified foundation for clinical and genomic data
Data Infrastructure
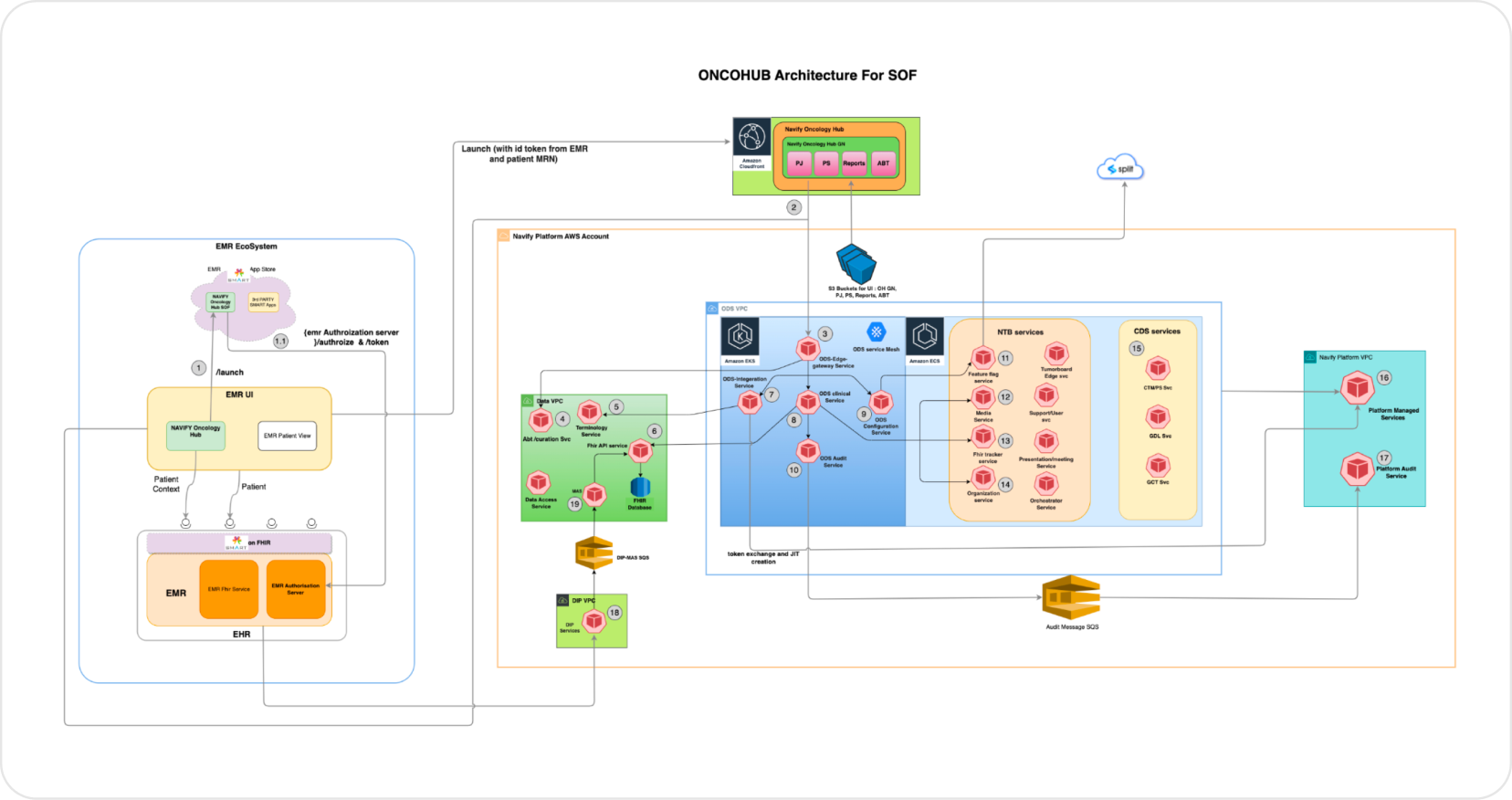
The first problem was scope. DeVero's codebase was large, test coverage was low, and every customer ran their own application stack. A big-bang rewrite would have The first problem was getting the data in one place without breaking compliance. Ideas2IT built a multi-region AWS data lake ingesting patient records from hospital chains, EMR systems, insurance providers, and diagnostic platforms.
- FHIR HL7-R4 conversion pipeline handling Medication Statements, Diagnostic History, and clinical records from multiple source systems
- Role-based access controls, AES-256 encryption, and a full audit trail service meeting HIPAA, GDPR, and 21 CFR Part 11 reporting requirements
- Dynamic task services on AWS ECS/EKS handling bulk FHIR operations, with Java microservices on SQS/SNS routing data to subscribed applications in real time
This phase produced
- Multi-region HIPAA/GDPR-compliant data lake
- FHIR HL7-R4 ingestion pipeline
- Real-time data routing layer
- Audit and compliance services
- Role-based access and encryption framework
Phase 02
Reducing patient-to-trial matching from weeks to hours
AI-Powered Trial Matching and Clinical Intelligence
With the data layer in place, Ideas2IT collaborated with MolecularMatch to build a precision-driven trial matching engine, then layered an NLP query platform on top so non-technical users could access the full data estate without SQL or BI tool dependency.
- Proprietary matching engine combining genomic, clinical, and histological data to rank trial eligibility in real time against ECOG scores, comorbidities, and resistance biomarkers
- Continuously refreshed trial database with REST APIs delivering recommendations directly into care team systems
- NLP interface translating plain English queries into SQL, with auto-generated visualizations and no BI tool dependency
This phase produced
- AI trial matching engine
- Real-time genomic and clinical data integration
- SQS and Kinesis async processing layer
- CDC-powered analytics pipeline
- Decoupled reporting data warehouse
Phase 03
Embedding intelligence at the point of care
Clinical Decision Support and Patient Journey Platform
The final layer brought the data to clinicians. Ideas2IT built an oncology guidelines platform unifying NCCN protocols with institution-specific pathways, and a longitudinal patient journey platform giving clinicians a complete view of each patient across treatments, diagnostics, and clinical events.
- Interactive flowchart interface with smart search, source-linked transparency, and custom pathway authoring across institutions
- NLP extraction from unstructured medical records surfacing structured insights across the patient timeline
- Configurable biomarker tracking and integrated document access within a single clinical interface, deployed across web and mobile
This phase produced
- NCCN and institutional protocol unification
- Interactive clinical flowchart interface
- Smart protocol search
- Custom pathway authoring
- Longitudinal patient journey visualization
- NLP extraction from unstructured records
- Mobile and web deployment
Building oncology software inside Roche means operating at a compliance standard and a delivery bar. Ideas2IT has been holding that standard for five years without exception and built every layer of the platform to it.
The Outcome
Roche's oncology platform runs on infrastructure Ideas2IT built and has maintained for five years. The compliance bar, the data scale, the integration complexity, and the delivery standard that a global pharmaceutical leader demands - Ideas2IT has held all of it. For any regulated healthcare engagement, that is the level Ideas2IT operates at.