

.avif)
TL'DR
In today's fast-paced digital world, managing and processing large volumes of documents efficiently is crucial for business success. Optical Character Recognition (OCR) technology has emerged as a key player in transforming how we handle paperwork, converting scanned documents, images, and PDFs into editable and searchable text. With a variety of OCR tools available, each offering unique features and capabilities, choosing the right one for your needs can be challenging.
Our comprehensive comparison of the best OCR tools delves into the top contenders, evaluating their performance, accuracy, and ease of use. Whether you're looking to streamline data entry, enhance document management, or integrate OCR into your existing systems, this guide will help you make an informed decision. Discover how these tools can boost productivity, reduce manual effort, and ultimately drive efficiency in your organization.
What is Robotic Process Automation (RPA)?
Robotic Process Automation (RPA) is a technology that leverages software robots or "bots" to automate repetitive and rule-based tasks traditionally performed by humans. RPA bots mimic human interactions with digital systems, enabling them to handle tasks such as data entry, transaction processing, and report generation with greater speed and accuracy.
The technology's ability to work across various applications without requiring deep integration makes it highly versatile, while its scalability enables businesses to adjust their automation efforts according to their needs.
How can OCR and RPA technology benefit your business?
OCR and RPA technologies can significantly enhance business operations by streamlining data management and automating repetitive tasks. Here’s how these technologies can benefit your business:
- Increased Efficiency: OCR technology automates the extraction of text from scanned documents, images, and PDFs, converting it into editable and searchable data. When combined with RPA, this data can be seamlessly integrated into various business processes, eliminating manual data entry and accelerating workflows thereby helping businesses react faster to market needs.
- Reduced Errors: Manual data entry is prone to human errors, which can lead to costly mistakes. OCR and RPA minimize these errors by automating data extraction and processing, ensuring higher accuracy and consistency in data handling. This also ensures that information is available in real-time, enabling faster decision-making
- Cost Savings: By automating routine tasks, OCR and RPA reduce the need for extensive manual labor, leading to significant cost savings. Businesses can reallocate resources to more strategic activities, improving overall operational efficiency.
- Enhanced Productivity: With OCR handling the task of data extraction and RPA managing repetitive processes, employees can focus on more complex and value-added activities. This boosts productivity and allows for a more efficient use of human resources.
- Increased Customer Support: Advanced OCR technology supports text recognition in various languages, empowering businesses to serve a global clientele effectively. By combining this with RPA, companies can enhance customer service through faster processing and reduced error rates. This seamless integration allows businesses to address customer inquiries and requests with greater speed and accuracy, leading to improved satisfaction and increased loyalty.
OCR Software Reviews
This blog is intended for developers/project managers/entrepreneurs who want to understand how different OCR services perform in terms of accuracy for image-based documents. This will also help them understand which OCR is useful for their requirement.
This blog will cover:
- challenges faced by us in identifying an OCR
- benchmarking statistics for different sets of image documents
- restrictions on each OCR service
- how to choose the appropriate OCR for gaining business traction
We are not getting into the details of
- Suggesting single OCR for all in one solution
- How does an entity extract the information?
- How to optimize input documents to improve OCR accuracy?
- If you don’t want to spend huge amounts of time benchmarking how different OCR services perform for their documents?
If you want to prioritize an OCR solution that has fewer restrictions for gaining business traction Then read on.
Key Challenges in Identifying an OCR Solution:
The challenges faced in the process of identifying an OCR and doing entity extraction are:
- Lack of original data for training and benchmarking. We derived a mockup solution that created training data that almost matched to original data
- Narrowing down business problems based on the severity
- Ceiling analysis on improving overall efficiency by allocating the optimum level of time needed for every module in the pipeline
- Designing core pipeline logic and breaking into micro modules
- Dynamic Pre and post-processing logic for image-based document
Benchmarking Statistics for Various Image Document Types:
Why Tesseract is the Best Open-Source OCR for MVPs
Tesseract is the best OCR software open source. When someone wants to get started with an open-source OCR to build an MVP, they can pick Tesseract as their first try. Tesseract is actively developed by a community and it is supported by Google (As of June 2019).
Recently neural net-based OCR engine mode is made available on Tesseract 4.0 which gives improved accuracy for image documents that have high noise (Not well-scanned documents).Will Tesseract help with all problems and all domains?
Tesseract 4.0 gives decent accuracy for well-scanned image documents but still, that accuracy might not be enough for gaining business traction. For example, implementing OCR-based solutions to the banking domain will have restrictions. Since Tesseract still has errors in determining financial numbers/currency/KYC information from the document, it might have a huge impact on errors in the finance domain.Preprocessing:
Also before feeding input image documents to Tesseract, we have to preprocess documents. Although some of the preprocessing logic are common (Increase dpi, grayscale, skewing or deskewing, etc.), we have to do a lot of preprocessing specific to document noise type. For instance, we have to apply filters to either increase the blur effect or decrease the blur effect based on how the image document is generated. We shouldn’t apply all preprocessing logic to one document which will decrease the accuracy. We can even use OpenCV and ImageMagick tools to achieve pre-processing logic.
Apart from preprocessing, we have to choose model parameters like page segmentation mode and OCR engine mode which are specialized to solve different document specifications and noise.
We have to derive an automated workflow solution to pick preprocessing steps and model parameters specific to document specification. If we can’t solve an automated workflow solution to pick preprocessing step and model parameters then we will end up with a lot of configuration specific to every document specification in your application.
Training Tesseract with lot of image
Choosing the best preprocessing step and model parameter will improve the accuracy of the Tesseract. But this accuracy might not be enough to solve some business problems!Training Tesseract with lot of image documents per document type (e.g license, invoice, bill) with manual marking of text will improve accuracy. The challenge here is for someone to have a huge amount of image documents and knowledge to train the Tesseracts neural net.
Google Vision Vs Microsoft OCR Vs Nuance OmniPage SDK vs ABBYY Finereader:
Both Google Vision and Microsoft OCR are leading online service providers for OCR tools. They both provide common features like text detection, object detection, document label detection, landmark detection, logo detection, etc. Both have the capability of yielding high-accuracy text extraction from noisy image documents (smudge, unclear text, skewed) like Identity documents.
Both Google Vision and Microsoft OCR services provide API endpoint to send the image document and return with JSON output which contains coordinate information along with text extracted. They both have good word segmentation and line segmentation. Due to decent word segmentation and improved accuracy of text detection, it will help the entity extraction module on the pipeline if any.
Both Nuance Omnipage and ABBYY FineReader are majorly used for on-prem OCR scanning software. Most clients prefer this on-prem OCR because they don't want their data to be transferred out of their firewall.Nuance OmniPage SDK comes with add-on features like OMR, document classification, ICR, and entity extraction RPA kind of tool. Whereas ABBYY Finereader is a plain vanilla OCR tool for text detection. So the pricing differs.
Both these applications are designed to support OCR extraction through the graphical user interface. The majority of the OCR work has to be run inside their desktop application. Nuance OmniPage SDK provides API to be integrated with your application. ABBYY FineReader provides hot folder functionality to batch process OCR files which might restrict the developer to achieve real-time extraction from image documents.
Evaluation of OCR Accuracy and Error:
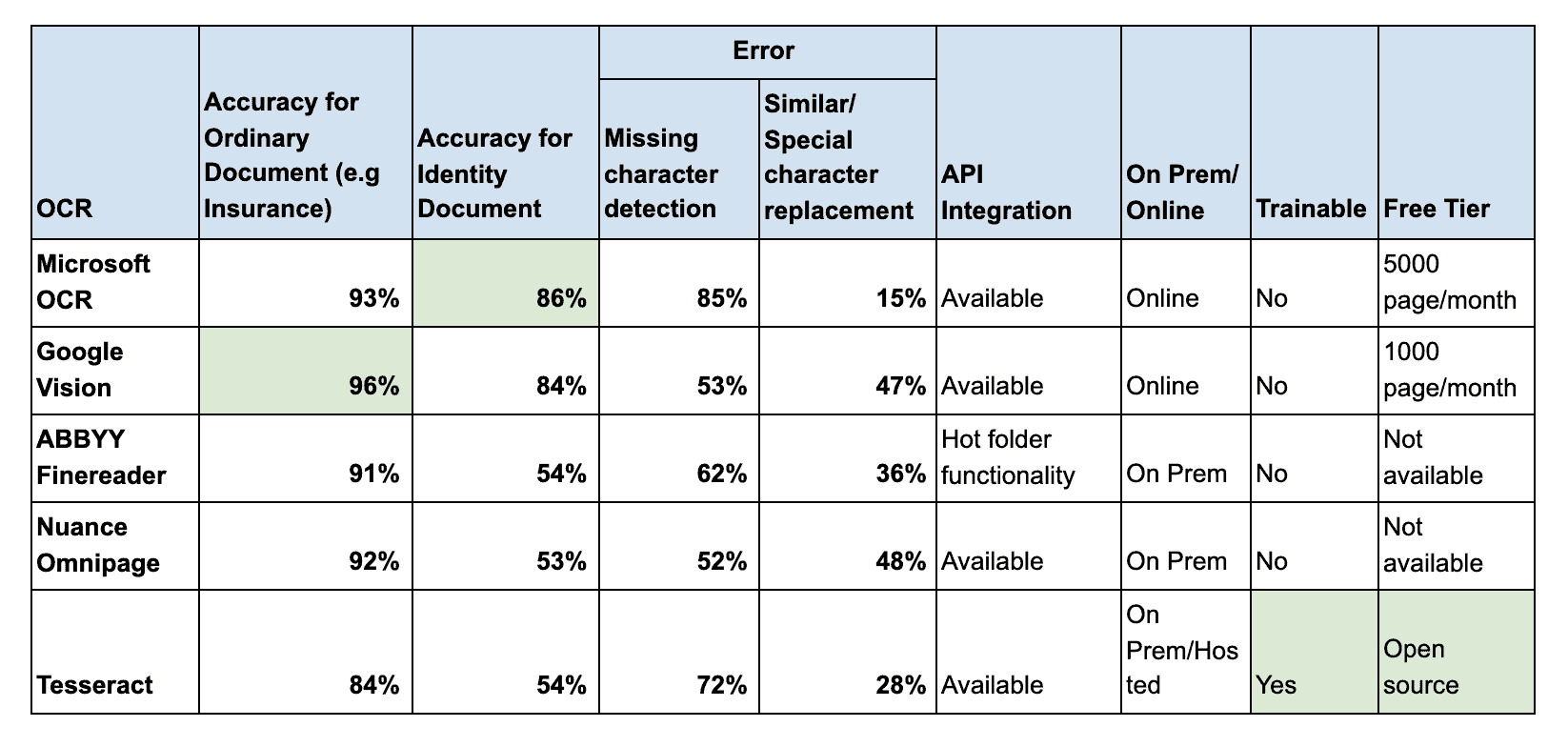
We have tried two types (Ordinary document and Identity Document) of the document on all five OCRs. Documents, like scanned insurance copy and invoice documents, are called Ordinary documents in our context. Whereas Identity documents are like driving licenses, and passport documents.Identity documents will have intended synthetic noise, so OCR accuracy will be less compared to ordinary documents.
The below figure shows accuracy stats for all five OCR services performed on different document types.

For both type of document, Google and Microsoft OCR performs well. For ordinary document Nuance and ABBYY FineReader performs well on par with Google and Microsoft OCR.
The below figure shows error classification for all five OCR services performed on different document types.
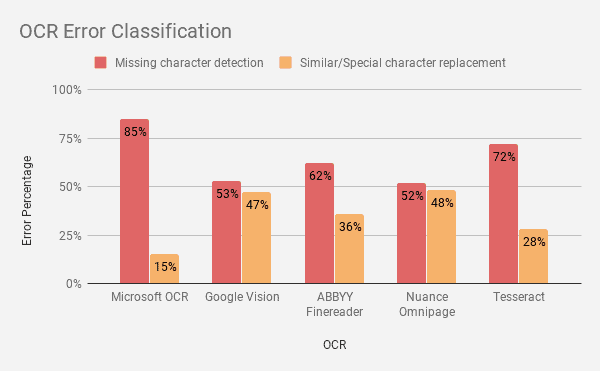
Microsoft OCR fails to detect some of the regions completely and is unable to recognize any text information from that region on the highly noisy image document. This can be a restriction when we rely only on Microsoft OCR for our application.
Microsoft OCR has 85% errors due to “missing character detection”. Whereas google Vision has 53% errors due to “missing character detection”. These errors are hard to be solved by NLP programs.Microsoft has 15% errors due to “similar/special character replacement” whereas Google Vision has 47% errors are due to “similar/special character replacement”. These errors can be reduced using the Nature Language Processing (NLP) program.
Both Nuance and ABBYY FineReader yield less accuracy for high-noise documents like Identity documents. When compared with Tesseract (Applying proper filter and model parameter for Tesseract) yield similar accuracy for high noise document.ABBYY Finereader has a 62% error due to “missing character detection” whereas Nuance OmniPage SDK has a 52% error due to “missing character detection”. These errors are hard to be solved by NLP programs.
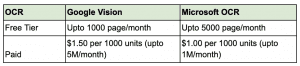
Pricing information:
Limitations of OCR Tools
While OCR tools offer transformative benefits, they come with their own set of limitations.
- One major challenge is accuracy, particularly with poor-quality or heavily formatted documents, which can lead to misinterpretation of characters and data.
- OCR tools also struggle with handwritten text, which often requires advanced algorithms to decipher accurately.
- OCR systems may not perform well with complex layouts, multiple columns, or unusual fonts, impacting their ability to capture data reliably.
- While OCR can process large volumes of data, it may require significant computational resources and manual review to ensure data integrity, particularly in cases of high error rates.

Builds strategic content systems that help technology companies clarify their voice, shape influence, and turn innovation into business momentum.



.png)
.png)
.png)
.png)
.png)













